
We want raw data now !
Tim Berners Lee au TED, février 2009
Le Web 2.0 n'existe pas et le Web 3.0 n'existera jamais. Le Web est le Web, c'est tout. Toujours le même et changeant sans cesse. Ne connaissant aucune révolution mais une évolution permanente.
Cependant, parler de Web 1.0, 2.0 et désormais 3.0 est devenu chose courante. Beaucoup d'observateurs utilisent cette terminologie qui a le mérite d'être un repère. Comme tout le monde en a sa propre interprétation (de Fred Cavazza à l'atelier informatique ou aux contributeurs de Wikipedia, etc.) et comme aucune ne se démarque réellement, je me propose de présenter ici ma propre vision de ce que ces termes signifient.
Je vais illustrer les différents "Web" avec des petits schémas où la rangée du haut représente les documents, celle du milieu les bases de données et celle du bas les créateurs de données.
Tout d'abord, établissons que dans le Web, les informations peuvent grossièrement être divisées en deux types : les données brutes et les documents.
Web 1.0 : des petits îlots
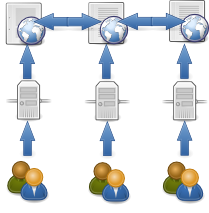
Dans le fonctionnement classique des sites Web, les données brutes (les "ressources") sont conservées captives dans des bases de données et ne sont utilisées que pour produire des documents (les "représentations") (au mieux en XML, le plus souvent en soupe HTML).
Tous ces documents représentent déjà une immense richesse qui a fait le succès du Web, mais leur potentiel d'exploitation est vraiment pauvre. Ils ne peuvent être en effet reliés que par des liens hypertextes, qui suffisent pour "surfer" mais qui sont trop peu qualifiés pour des usages plus avancés.
Le Web 1.0 est le Web des pages personnelles (Geocities, Multimania), des hébergeurs pour particuliers ou PME (OVH, 1&1), des applications Web à installer soit-même (Wordpress, Joomla, Dotclear, ZenPhoto), et de certains services de publication ou d'hébergement de contenu où les comptes ne sont pas interconnectés (Skyblog, LiveJournal). C'est aussi celui de Google, dont les algorithmes se basent sur l'analyse des documents et le réseau de liens hypertextes.
Web 2.0 : des gros silots
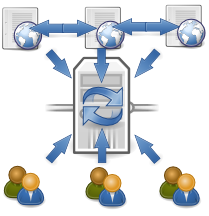
Le passage au Web 2.0 repose sur l'idée que les données doivent aussi être reliées et exploitées. Comme les base de données sont toujours cloisonnées, on a trouvé pertinent d'en créer de plus grosses, de bien plus grosses. Ce furent les réseaux sociaux (Twitter, Facebook, MySpace, LinkedIn, Flickr, Last.fm...).
Ainsi, deux utilisateurs d'un même réseau social vont pouvoir partager plus que de simples documents, plus que s'ils avaient leur sites personnels chacun dans leur coin. Ils vont pouvoir accéder à de nouvelles informations, issues des rencontres de leur données respectives au sein de la grande base. C'est ce qui fait leur attrait et leur succès.
Cependant, même de très grandes bases de données restent toutes petites comparées à l'immensité du Web. Et l'émiettement demeure, même s'il se réduit. Les utilisateurs se retrouvent donc obligés d'entretenir des comptes sur plusieurs réseaux, ce qui est contre-productif.
De plus, cette création de richesse informationnelle est en grande partie captée par les entreprises derrière ces réseaux sociaux, qui refusent ensuite d'en faire disposer librement leurs propriétaires légitime. Il y a une perte de contrôle sur ses propres données, une forme d'esclavage 2.0.
C'est donc une fausse bonne solution.
Web 3.0 : des ponts entre les petits îlots
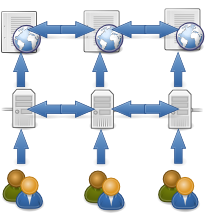
Ma vision pour le Web 3.0, c'est le retour à un Web composé d'une nébuleuse décentralisée et démocratique de sites, notre bon vieux Web, avec une exposition des données brutes de ces sites afin de les interconnecter et de créer des synergies bien plus riches que celles présentes aujourd'hui au sein des réseaux sociaux.
Il y a plusieurs moyen d'y arriver :
- La solution la plus simple est de produire, en parallèle des documents, des fichiers contenant les données brutes (comme le propose Triplify);
- Une autre solution est d'intégrer ces données brutes directement dans les documents (avec des attributs RDFa, une technologie déjà évoquée dans ce carnet quand elle était encore embryonnaire);
- Mais la véritable audace est l'ouverture des bases de données elles-mêmes (ou du moins leur partie intéressante et non dangereuse) en proposant un accès à un end-point. Je ne m'attarderai pas sur les détails techniques de cette solution car ma connaissance du sujet est encore maigre.
Tout ceci relève de l'initiative naissante Linked Data, qu'il faut coupler avec des technologies d'authentification et d'autorisation afin d'obtenir un service équivalent au réseaux sociaux.
Ceci ne signera pas la fin de ces grands réseaux qui peuvent eux aussi se conformer à ces nouveaux principe, mais je veux croire que le Web 3.0 sera celui des petits systèmes de gestion de contenus ultraspécialisés et ultraouverts.
Actuellement, le Web 3.0 est le Web de Yahoo! (grâce à SpiderMonkey), des grandes bases de données décloisonnées comme DBpedia, et de CMS d'avant-garde comme Drupal.